![]()
Apache Hadoop has revolutionized the way we handle big data, offering a robust framework for distributed storage and processing of large datasets. Whether you’re a data scientist, software engineer, or IT professional, understanding how to install and configure Hadoop is an essential skill in today’s data-driven world. This guide will walk you through the process of installing Apache Hadoop on Ubuntu 24.04, providing detailed instructions, troubleshooting tips, and best practices to ensure a smooth setup.
Introduction
Hadoop’s ability to process vast amounts of data across clusters of computers has made it a cornerstone technology for businesses and organizations dealing with big data analytics. By following this guide, you’ll be able to set up a single-node Hadoop cluster on your Ubuntu 24.04 system, laying the foundation for more complex distributed computing tasks.
Prerequisites
Before we dive into the installation process, ensure that your system meets the following requirements:
- Ubuntu 24.04 LTS installed and updated
- Root or sudo access to the system
- A minimum of 4GB RAM (8GB or more recommended)
- At least 10GB of free disk space
- A stable internet connection
Update and Upgrade Ubuntu System
Start by updating your Ubuntu system to ensure you have the latest packages and security updates. Open a terminal and run the following commands:
sudo apt update
sudo apt upgrade -yThis process may take a few minutes, depending on your internet speed and the number of updates available.
Install Java Development Kit (JDK)
Hadoop requires Java to run, so we’ll need to install the Java Development Kit. While Hadoop is compatible with various Java versions, we’ll use OpenJDK 11 for this installation.
sudo apt install openjdk-11-jdk -yAfter the installation completes, verify the Java version:
java -versionYou should see output similar to this:
openjdk version "11.0.11" 2021-04-20
OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.24.04)
OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.24.04, mixed mode, sharing)Next, set the JAVA_HOME environment variable:
echo "export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")" | sudo tee -a /etc/profile
source /etc/profileVerify that JAVA_HOME is set correctly:
echo $JAVA_HOMECreate a Hadoop User
It’s a good practice to create a dedicated user for Hadoop operations. This enhances security and simplifies management.
sudo adduser hadoop
sudo usermod -aG sudo hadoopSwitch to the new hadoop user:
su - hadoopConfigure SSH
Hadoop requires SSH access to manage its nodes. We’ll set up passwordless SSH for the hadoop user:
ssh-keygen -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysTest the SSH setup:
ssh localhostIf successful, you’ll be logged in without being prompted for a password. Type ‘exit’ to return to your original session.
Download and Install Hadoop
Now, let’s download and install Hadoop:
wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.4.1/hadoop-3.4.1-src.tar.gz
tar -xzvf hadoop-3.4.1-src.tar.gz
sudo mv hadoop-3.4.1 /usr/local/hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoopConfigure Hadoop Environment Variables
Add Hadoop environment variables to your .bashrc file:
echo "export HADOOP_HOME=/usr/local/hadoop" >> ~/.bashrc
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.bashrc
echo "export HADOOP_MAPRED_HOME=\$HADOOP_HOME" >> ~/.bashrc
echo "export HADOOP_COMMON_HOME=\$HADOOP_HOME" >> ~/.bashrc
echo "export HADOOP_HDFS_HOME=\$HADOOP_HOME" >> ~/.bashrc
echo "export YARN_HOME=\$HADOOP_HOME" >> ~/.bashrc
source ~/.bashrcConfigure Hadoop Files
Now, we’ll configure the core Hadoop files. Open each file with a text editor and add the specified content:
core-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAdd the following configuration:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAdd the following configuration:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>mapred-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlAdd the following configuration:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>yarn-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlAdd the following configuration:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>hadoop-env.sh
Update the JAVA_HOME path in the hadoop-env.sh file:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.shAdd or modify the JAVA_HOME line:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Format Hadoop Filesystem
Before starting Hadoop services, we need to format the Hadoop filesystem:
hdfs namenode -formatYou should see a message indicating successful formatting of the namenode.
Start Hadoop Services
Now, let’s start the Hadoop services:
start-dfs.sh
start-yarn.shThese commands will start the NameNode, DataNode, ResourceManager, and NodeManager services.
Verify Hadoop Installation
To verify that Hadoop is running correctly, use the following command:
jpsYou should see output similar to this:
12345 NameNode
23456 DataNode
34567 ResourceManager
45678 NodeManager
56789 SecondaryNameNode
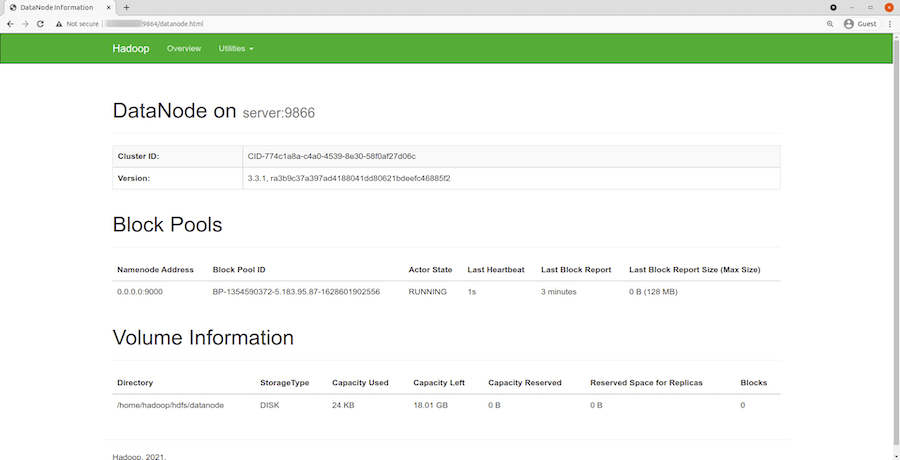
67890 JpsAdditionally, you can access the Hadoop web interfaces:
- NameNode:
http://localhost:9870 - ResourceManager:
http://localhost:8088


Troubleshooting Common Issues
While installing Hadoop, you might encounter some common issues. Here are a few troubleshooting tips:
Java Version Conflicts
If you see errors related to Java version incompatibility, ensure that you’re using a compatible version of Java and that JAVA_HOME is set correctly.
SSH Configuration Problems
If Hadoop services fail to start due to SSH issues, double-check your SSH configuration and ensure that passwordless SSH is working correctly.
Port Conflicts
If you see errors about ports being in use, make sure no other services are using Hadoop’s default ports. You may need to modify the port settings in the configuration files.
Permission Issues
Ensure that the hadoop user has the necessary permissions to access all Hadoop directories and files.
Congratulations! You have successfully installed Apache Hadoop. Thanks for using this tutorial for installing Apache Hadoop on Ubuntu 24.04 LTS system. For additional help or useful information, we recommend you check the official Apache Hadoop website.